一、引言:元数据——数据仓库的“导航系统”
在数据仓库(Data Warehouse)的复杂生态中,元数据(Metadata)扮演着“关于数据的数据”这一核心角色。它如同地图与指南针,记录了数据的来源、格式、含义、血缘关系、转换逻辑和使用情况。高效管理元数据,是确保数仓数据可发现、可理解、可信赖、可管理的关键,直接影响数据分析的效率和决策的准确性。
二、元数据管理的核心价值
- 提升数据发现与理解效率:通过业务术语表、数据字典,用户能快速定位和理解所需数据。
- 保障数据质量与血缘追溯:清晰的数据血缘(Data Lineage)能追踪数据从源系统到最终报表的完整路径,便于问题定位与影响分析。
- 加强数据治理与合规:明确数据所有者、敏感等级、生命周期策略,满足合规审计要求。
- 优化系统运维与开发:为ETL任务调度、存储优化、模型变更提供依据。
三、数仓元数据管理体系构建
1. 元数据的分类与采集
- 技术元数据:库表结构、字段类型、ETL作业信息、调度依赖、SQL脚本等。通常通过连接数仓引擎(如Hive MetaStore)、调度工具API、解析SQL日志自动采集。
- 业务元数据:指标定义(如“日活跃用户”的计算口径)、业务术语、报表描述、数据域划分。需与业务部门协同梳理和维护。
- 操作元数据:数据访问频次、作业执行时长与状态、存储消耗、数据热度。通过监控系统和日志分析获得。
2. 核心管理流程
- 统一存储与建模:建议建立独立的元数据中心或采用专业元数据管理平台,设计合理的元模型,关联技术、业务、操作元数据。
- 自动化采集与同步:利用钩子(Hooks)、监听器、API接口实现元数据变更的实时或定期同步,减少人工维护成本。
- 血缘分析与影响分析:自动解析SQL、ETL脚本,构建从数据源→ODS→DWD→DWS→ADS的完整血缘图谱。当某表结构变更时,能快速评估对下游的影响范围。
- 版本控制与变更管理:对重要的数据模型、ETL逻辑、业务规则进行版本化管理,记录变更历史与原因。
3. 工具与平台选型
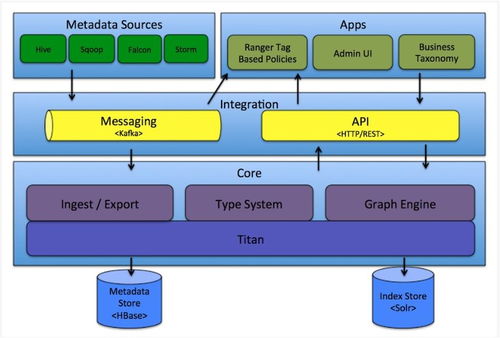
- 开源方案:Apache Atlas(与Hadoop生态集成度高)、DataHub(LinkedIn开源,现代架构)、Amundsen(Lyft开源,侧重数据发现)。
- 商业产品:Informatica Metadata Manager、Collibra、Alation等,功能全面,企业级支持完善。
- 自建平台:基于数据库设计元模型,开发采集、展示、搜索功能,灵活性高但投入较大。
四、落地实践建议
- 分阶段实施:从核心业务线或痛点明显的领域(如报表数据不一致)入手,先建立关键数据资产的血缘和字典,再逐步扩大范围。
- 建立组织与流程:明确数据Owner职责,建立元数据申请、审核、发布、变更的流程规范。
- 与数据治理结合:将元数据管理与数据质量监控、主数据管理、数据安全等级分类等工作联动。
- 推动数据文化:通过易用的数据目录门户,鼓励业务人员主动搜索和使用可信数据源,让元数据管理产生业务价值。
五、文末彩蛋:数据处理与存储支持服务浅析
高效的元数据管理离不开底层稳健的数据处理与存储服务支持。现代数仓架构中,这些服务呈现出以下趋势:
- 处理层:
- 实时化:Flink、Spark Streaming等流处理引擎的普及,使得实时数据管道与批处理管道并存,元数据需统一管理两类任务。
- 云原生与Serverless:基于云服务的弹性数据处理服务(如AWS Glue、Azure Data Factory),降低了运维负担,其执行元数据也需纳入管理范围。
- 一体化:Databricks、Snowflake等平台将计算、存储、管理深度集成,提供了原生的元数据管理能力。
- 存储层:
- 湖仓一体(Lakehouse):以Delta Lake、Apache Iceberg、Hudi为代表的表格式,在数据湖存储之上实现了类似数仓的ACID事务、元数据管理能力,使得元数据管理需向下延伸至文件层级。
- 对象存储成为主流:S3、OSS等因其无限扩展性和成本优势,成为底层存储标准,其上的元数据抽象与管理至关重要。
- 智能分层与优化:基于操作元数据(如访问热度),自动将数据在热、温、冷存储层间移动,以优化成本与性能。
彩蛋核心启示:元数据管理与底层数据处理、存储服务的设计紧密耦合。在选择或构建数仓架构时,应优先考虑那些提供开放、可扩展元数据接口的组件与服务,确保整个数据栈的元数据能够被统一采集、关联和分析,从而真正释放数据资产的价值。
##
元数据管理并非一蹴而就的技术项目,而是一项需要持续投入的、业务与技术融合的体系性工程。它始于技术,但成于治理,终于价值。一个活跃、准确、全面的元数据系统,将是企业数据驱动能力的坚实基石。